I spent a year telling teams "you need network policy" while quietly running clusters without it myself. The iptables-era Calico policies that broke DNS at 2 AM had burned me enough times, and every AKS cluster eventually hits the question "do we actually know what traffic is happening inside this cluster?" The honest answer is usually no, since the tooling has historically been expensive and operationally painful.
Nearly every AKS cluster I've worked with runs with minimal meaningful network segmentation. Platform teams understand the security argument perfectly, but they're afraid, and for good reason. Badly designed network policies create outages that echo for weeks. Troubleshooting why a pod can't reach a database through a policy wall is miserable work without visibility, and visibility has historically meant building custom observability stacks or relying on overlay assumptions that break under pressure.
So teams make a calculated choice: they skip segmentation and accept the risk, buying better identity controls, more granular RBAC, supply chain security, workload attestation instead. But East-West traffic segmentation inside the cluster stays loose since the operational cost of getting it wrong is just too high.
Cilium changes that calculation, not by making network policy magical (policy is still policy and bad policy still breaks things), but by giving you two things that were always theoretically possible yet operationally hard: real visibility into what traffic is actually happening, and a more direct enforcement path that makes troubleshooting less like hexing your cluster and more like debugging a real system. Azure has made this easier by integrating Cilium into AKS. Azure CNI powered by Cilium is basically the modern path forward. If you're building a serious AKS platform in 2026, you need to understand what Cilium actually gives you, what it doesn't, and whether the operational path from "we have no policy" to "we have reasonable segmentation" is worth the effort. Spoiler: it is, if you do it right.
The Networking Confusion Problem
A lot of platform teams think in CIDR ranges and subnet planning when pod connectivity is already solved. The real unsolved problem is what traffic should be happening.
Teams say they want "zero-trust networking," but what they actually do is write three or four policies that feel safe, then call the problem solved. They don't write more since, without visibility into actual traffic, writing policy against imaginary topology is a losing game. You guess at flows, it works for three months, a new service breaks everything, and after a few debugging sessions the team loosens the policies or disables them entirely. For years, the tools just didn't give you good enough visibility to write policy with confidence.
The other confusion is layering. You've got the network itself (Azure CNI providing IP allocation and routing) and a policy engine (Calico, Cilium, or nothing), and these are separate concerns. If you're curious about the differences, I wrote about that in my previous post on AKS network plugins. Cilium doesn't make policy easier to write, but it makes understanding whether your policies are doing what you intended much more tractable.
What Does Azure CNI Powered by Cilium Actually Change?
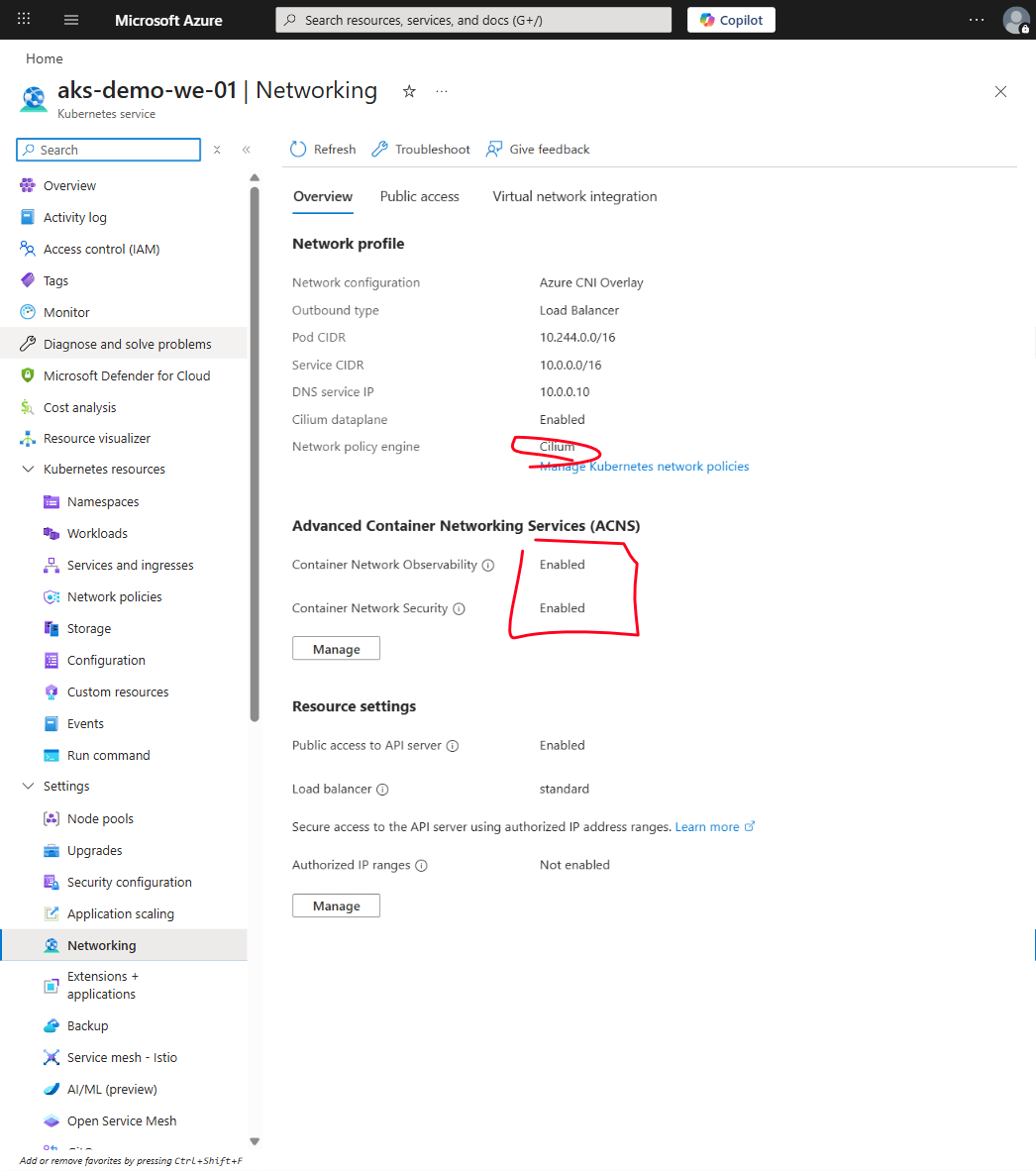
At its core, Cilium uses eBPF to handle Kubernetes networking and network policy, and Azure CNI powered by Cilium means Azure runs it on your behalf, taking care of pod-to-pod connectivity, policy enforcement, and traffic observability. The architectural shift compared to older approaches like Calico is that Cilium doesn't use iptables chains to enforce policy. Instead, policies are compiled into eBPF bytecode and executed directly in the Linux kernel. Iptables chains have fundamental scaling and visibility limits, while eBPF code runs closer to actual packet processing and can collect richer telemetry.
From an operational perspective, let me walk through the key things you get:
Native policy enforcement at the kernel level. When you define a Kubernetes NetworkPolicy, Cilium compiles it into eBPF and loads it into the kernel. Enforcement happens in the data path, not as a post-hoc layer on top of routing, so no more wondering whether your iptables chain ordering is messing things up.
Direct visibility into dropped traffic. Cilium instruments the kernel to report on flows that are denied by policy, flows that are allowed, and flows that fail for other reasons. You can query these metrics directly from managed Prometheus or through Azure Monitor, and you actually see which pods are generating denied flows, at what rate, and why. No more guessing.
DNS-aware policy (requires ACNS). You can write policies that say "pods in the data namespace can make HTTPS calls to external.service.com, but nothing else." Cilium tracks DNS responses and applies policy at the DNS level, not the IP level, which is much more useful for controlling egress when you don't control the destination IPs. Now, FQDN-based filtering isn't available with base Cilium on AKS. You need Advanced Container Networking Services enabled for that.
Layer 7 visibility and policy (requires ACNS). Cilium can understand HTTP, gRPC, Kafka, and other application protocols, so you can write policies that say "the web pod can make GET requests to the API pod, but not DELETE." Way more granular than network-level policy, but also more expensive to compute, which is why it's not the default.
Integrated observability (requires ACNS). With ACNS enabled, Cilium exposes Hubble metrics about flows, drops, DNS resolutions, and connection rates to managed Prometheus. Without ACNS, you get basic Cilium agent metrics (node-level drops and forwards) but not the pod-level Hubble observability that makes policy rollout manageable. ACNS is a paid add-on, so budget accordingly.
What I find most useful in practice is how these pieces work together: I can observe what traffic is happening, write policy to enforce what I want, and then actually audit and troubleshoot when something goes sideways. That combination just wasn't realistic with iptables-era tooling.
What Cilium Doesn't Solve
Cilium is an excellent tool for a specific set of problems, but it won't fix everything, and I've seen teams learn this the hard way.
If your application makes unexpected network calls, Cilium will tell you about it, but it won't change the application to make better calls. You've got a monolithic service talking to every database and external service? Cilium will let you write policy to block those calls, and then your application will fail. You'll have learned something useful, but the real fix is architecture work, not network policy.
Authentication and authorization are a different problem entirely. Network policy controls whether a connection can be established, but it doesn't control what happens after. If you need to ensure that a pod can connect to a database but can only read certain tables, that policy lives in the database, not in Cilium. Overpermissive identity is another blind spot: a service account with broad RBAC permissions or a pod with ambient credentials that grants access to many resources. Cilium won't catch that since it works inside the cluster on pod-to-pod traffic, and that's its lane, so don't ask it to be something it's not.
And finally, policy requires knowing what your applications should be doing. You need that specification, that confidence about what traffic should happen, since without it writing policy is just guessing and hoping. You can figure that out with the observation phase, but the point stands.
Where I've Seen Teams Get It Wrong
The teams that fail at network policy implementation fail in predictable ways, and I've been guilty of a few of these myself :)
Writing policy without understanding application behavior is the number one killer. You write policies based on how you think the application should behave, not how it actually behaves, and then production breaks since reality doesn't match your assumptions. The fix is straightforward: run in audit mode first and observe actual traffic before enforcing anything.
Every egress policy needs UDP/53 to kube-system. Miss it and your pods can't resolve names, turning your segmentation policy into a DoS on your own cluster. This gets everyone at least once.
Then there's the assumption that DNS names are stable. A policy that says "allow egress to api.example.com" only works if DNS resolution is stable, and if the IP address changes, the policy might not match. This is especially risky with dynamic DNS, anything behind a load balancer or CDN. Use Cilium DNS policy matching instead of IP-based rules.
Going too restrictive too fast will also burn you. A policy that says "allow only this specific destination" is fragile. If the application needs a new destination, the policy blocks it and you've got a production outage. So be generous with legitimate internal traffic, strict with external egress, and tighten over time.
Testing policy changes in production without a rollback plan is reckless. Sometimes staging doesn't perfectly mirror production, but you still need to try. Use a test cluster that mirrors production topology and test there first.
Observe First, Enforce Later
Alright, this is the whole principle and I can't stress it enough: observe your traffic for a good long while before you start blocking anything. I learned this one the hard way after locking out an entire namespace from DNS on a Friday afternoon. You do that once and the lesson sticks :)
The workflow is:
Deploy Cilium with ACNS enabled for Hubble observability. Don't apply any policies yet, just let Hubble capture actual traffic patterns.
Run observation for at least two weeks, collecting metrics about what egress traffic the cluster is actually making. This part requires patience but it's non-negotiable.
Analyze the data: which namespaces are making external calls, what destinations are common, and are there any unexpected patterns?
Write policies based on observed traffic, not imagined traffic. Enable daemon-wide audit mode via Helm (policyAuditMode=true) to test policies without blocking traffic.
Test policies in a staging cluster that mirrors your production topology.
Deploy to production with a rollback plan.
The reason this workflow matters is that it prevents you from writing policies that break your applications by accident. Cilium, ACNS, and managed Prometheus integration makes steps 2 and 3 feasible, so you can actually see:
DNS requests and responses
Initiated connections and their destinations
Allowed and denied flows
Policy decision rates by namespace and pod
I've watched teams skip the observation phase and jump straight to enforcement, and the result is always the same: a production outage followed by policies getting disabled entirely.
Basic Policy Architecture
graph LR
U["External Users"] --> W["web pods\nport 443"]
W --> A["api pods\nport 8080"]
A --> D["data pods\nport 5432"]
style U fill:#f9f,stroke:#333
style D fill:#bbf,stroke:#333
For concreteness, imagine an AKS cluster with three namespaces:
web: Frontend services that accept traffic from external users
api: Backend API services that process requests
data: Databases and data stores
The intended traffic flow is: users make requests to web, web calls api, api calls data. Nothing else should talk to anything else, and external traffic should only enter via the web namespace.
Start with standard Kubernetes NetworkPolicy. Here's a basic policy that isolates the API namespace:
Standard NetworkPolicy is sufficient for basic segmentation, but the limits come when you want DNS-aware egress control, Layer 7 policy, or more granular metrics, which is where CiliumNetworkPolicy extends the model.
CiliumNetworkPolicy: DNS and Layer 7
CiliumNetworkPolicy allows richer policy definitions, and this is where things get actually interesting. One important heads-up: L3/L4 CiliumNetworkPolicy works with base Cilium on AKS, but FQDN filtering and L7 HTTP policy require Advanced Container Networking Services (ACNS) to be enabled.
Egress policy with DNS names (allowing only HTTPS to a specific external domain, requires ACNS):
Cilium uses an implicit default-deny model when any egress rule is specified, so only traffic matching the explicit allow rules gets through and everything else is dropped.
Layer 7 HTTP policy (allowing only GET and HEAD requests from web to API, requires ACNS):
All egress not matching these rules is implicitly denied, which is clean and predictable.
Observing Policy Decisions
Once Cilium is running and policies are in place, the operational win is observability. Cilium exports metrics about policy decisions, allowed flows, denied flows, and DNS resolutions, and this is what makes the whole approach viable.
Key metrics for troubleshooting (Hubble metrics require ACNS):
hubble_drop_total: Dropped packets by reason and protocol (pod-level), which is your first stop when something breaks
hubble_flows_processed_total: Processed flows by verdict, forwarded or dropped (pod-level)
hubble_dns_queries_total and hubble_dns_responses_total: DNS queries and responses with return codes observed by Hubble (pod-level)
cilium_drop_count_total: Node-level dropped packet count by reason and direction
Useful PromQL queries:
Dropped flows by reason:
sum(rate(hubble_drop_total[5m])) by (reason)
Dropped flows from a specific source:
sum(rate(hubble_drop_total{source=~"web/.*"}[5m])) by (reason, protocol)
DNS queries by domain:
sum(rate(hubble_dns_queries_total[5m])) by (query)
Node-level drops by reason and direction:
sum(rate(cilium_drop_count_total[5m])) by (reason, direction)
I can't overstate how important this observability layer is during rollout. Before you enforce policy, you need to see what's being dropped and why. These PromQL queries aren't nice-to-haves, they're your safety net during the entire rollout. That being said, this also means ACNS is pretty much a prerequisite if you're serious about policy. You can find more about the Hubble metrics reference here.
The Rollout: Stage by Stage
I deploy policy in stages every time, since jumping straight to enforcement will break things. I guarantee it.
Stage 1: Baseline Capture (Week 1). Deploy Cilium with ACNS enabled but no policies yet. Just let Hubble capture what's actually happening while you run standard workloads, run the test suite, and collect metrics on DNS requests, external egress, and internal traffic.
Stage 2: Policy Definition (Week 2-3). Based on observed traffic, define namespace-level policies. Start with deny-all-ingress-by-default, allow specific namespaces, and do this in staging if possible. This is where the observation data from Stage 1 pays off, since you're writing policy against reality instead of assumptions.
Stage 3: Audit Run in Production (Week 4-5). Enable Cilium's policy audit mode cluster-wide via Helm (policyAuditMode=true) or per-endpoint via cilium-dbg endpoint config. In audit mode, Cilium evaluates traffic against policy but doesn't block anything, it just logs what would be denied. Monitor those would-be denials carefully. If something is being flagged a lot, the policy is incomplete. I found this stage to be the most educational, you learn things about your application topology that nobody documented :)
Stage 4: Refinement. Now, adjust policies based on what you learned. Allow cross-namespace traffic if needed, add external DNS names to allowed egress, and add kube-system namespace access for DNS.
Stage 5: Enforcement (Week 6). Once denial rates are stable and low, switch to enforcement. Have a rollback plan, commit to a week of close monitoring, and watch for spikes in denials during normal operations.
The entire process typically takes 6-8 weeks from start to enforcement (sometimes longer in regulated environments), which sounds long, but it prevents outages. I'll take "slow and boring" over "fast and on-call at 3 AM" every time.
eBPF vs iptables: Why This Matters
iptables rules are stored as linked lists, so every packet checks rules sequentially and performance degrades as rule count grows. Policy is basically a layer bolted on top of networking, not integrated with it.
eBPF compiles policy into bytecode that runs directly in the kernel with JIT compilation at near-native speeds, using hash table lookups instead of sequential scans. The result: Cilium enforces policies faster with richer observability, and performance stays constant regardless of rule count. That's a big deal when you're running hundreds of policies across dozens of namespaces.
Anti-Patterns That Will Bite You
Assuming policy is free. Cilium adds CPU and memory overhead, and sensor telemetry scales with pod count and behavioral complexity (roughly linear with active endpoints). Before deploying sensors cluster-wide, understand your cost implications. Actually run the numbers on node resource consumption before you flip the switch, not after.
Not documenting why policies exist. Six months after writing a policy, you'll forget why it needs to be so specific. So add annotations explaining the business or operational reason the policy exists. Future you will be grateful (or at least less confused).
Setting alert thresholds on denied traffic that are too low. If policy is working correctly, denied traffic should be rare but not zero. You'll have legitimate tests, health checks, and retry logic that generates denied traffic, so set thresholds based on baseline patterns, not zero.
Writing policies so permissive that they're useless. A policy that allows everything isn't policy. Be willing to tighten constraints and iterate, even if it means a few rounds of adjustments during the first month.
Over-using L7 policy. Layer 7 inspection is compute-intensive, adding latency and CPU. Use L7 policy only when you've got a specific security requirement that can't be met with L3/L4 rules. Don't just turn it on since it sounds cool.
When Policy Breaks Things
When policy starts blocking traffic you didn't expect:
I for one went from zero network policy to reasonable segmentation across my clusters over the span of a few months, and the difference in operational confidence is real. Not since I suddenly have perfect security (nobody does), but since I can actually see what's going on inside the cluster and make informed decisions about what to block.
Here's why the calculation has shifted: observability changed the game. Five years ago, network policy meant deploying a policy engine and hoping you got the rules right. If something broke, debugging took hours or days, so the risk was high enough that I just skipped it.
Today, with Cilium, ACNS, and managed Prometheus, you can observe actual traffic, deploy policies in audit mode, and make informed decisions about what to enforce. The operational risk dropped significantly. Deployment is still a multi-week effort, but it's a manageable, well-documented process.
Azure has made this easier by integrating Cilium into AKS. The path from "we have no policy" to "we have reasonable segmentation" is now standard. Not easy, but standard, and there's a real difference between those two things.
Start small: one namespace, one week of audit mode, one policy. Establish visibility first with enforcement much later. After three months of operations, after you've seen policies actually stop traffic that should be stopped and understand your application topology better through the lens of policy, you'll understand that the effort was worth it.
Node image retirement is not an emergency if you treat it as a predictable operating model. How to migrate images without chaos, what to test, and how to govern the decision.
APIM isn't just a gateway. It's a governance layer that enforces consistency across AKS, Container Apps, and other platforms. When to use it and when to keep things simple.
Runtime security is not posture; learn how Defender bridges the gap between admission controls and what containers actually do at runtime, and when the observability it provides actually matters for real threat response.









{kind=link}